作者简介:李润生,男,安徽合肥人,北京中医药大学人文学院法律系副教授,法学博士,研究方向:卫生健康法、网络数据法。
摘要:通用模型带来了深刻的“范式变革”,“预训练+微调”成为人工智能发展的新范式,这引发了真正的通用性革命。通用模型的实践应用也带来了各种新风险,并经由模型和数据之转介放大了既有风险。然而,通用模型的法律治理仍处于早期阶段,包括我国在内的绝大多数国家或地区尚未将通用模型纳入规制体系,这是当下面临的最大现状和挑战。我国应当明确将通用模型提供者纳入规制体系,消弭法律制度与技术现实之鸿沟,并立足于通用模型的技术特性及体系定位,精准、适度赋予法律义务,实现制度安全与技术创新之平衡。结合医疗领域之特色和先例,我国应当尽快推进通用模型的立法涵摄,构建两阶段的准入审核体系。第一阶段为通用模型的准入审核,坚持内在评价,审查重点在于模型架构的科学性、数据治理的有效性、训练方法的适当性、开发组织的合规性等过程性事项;第二阶段为应用系统的准入审核,坚持外在评价,审查重点在于具体诊疗场景下预期用途和核心功能的达成性,审查方式为临床试验等结果性评价机制。医疗领域的规制方案可结合其他行业、领域的特性进行示范迁移。
关键词:通用模型;范式变革;立法涵摄;内在评价;医疗领域
引言
2022年末,ChatGPT横空出世,它的惊人能力引得举世瞩目。2025年初,DeepSeek风暴再次席卷全球,在东西方市场同时实现了现象级爆发。事实上,ChatGPT和DeepSeek只是浮出水面的冰山一角,更重要的则是隐于水下的部分,ChatGPT和DeepSeek应用系统分别是由GPT和DeepSeek模型微调而来的一个具体应用,后者具有孕育无数类似应用的巨大潜力。就技术范畴而言,GPT和DeepSeek模型属于基础模型(foundation model),或称大模型(large model)、生成式人工智能模型(generative AI model),斯坦福大学人工智能研究中心(Stanford Institute for HumanCentered Artificial Intelligence,HAI)将其界定为一种新型人工智能,它通过在大量无标注数据上进行预训练获取通用能力,进而通过少量标注数据的再训练即可适应广泛的下游任务,包括在训练时未预见和设定的新任务。相较之下,传统人工智能属于特定任务模型(fixed task model),仅能完成预先设定的特定任务,不具有广泛的适应性。就法律范畴而言,欧盟《人工智能法案(Artificial Intelligence Act)》采行了“通用目的人工智能模型(general purpose AI model,以下简称通用模型)”的术语,即“在大量数据上进行大规模自我监督训练的、展现出显著通用性的、能够胜任各种不同任务并可集成到各种下游系统和应用中的人工智能模型”。此处之“通用”意指“任务”之“通用”,而非“领域”之“通用”,前者指计算机任务处理的不同类别,包括文本生成、文本分类、情感分析、机器翻译、图像分类、图像检测、语音识别等;后者指应用场景或行业的不同类别,包括医疗保健、交通运输、教育国防等。同一“任务”可以覆盖多元“领域”,同一“领域”亦需处理多种“任务”。“大型生成式人工智能模型是通用模型的典型范例(但非全部),因为它们可以灵活地生成内容,如文本、音频、图像或视频等,可随时适应各种不同的任务。”应当指出,模型(model)不同于系统(system),二者是上下游概念,DeepSeek模型位于DeepSeek系统之上游。虽然人工智能模型是人工智能系统的重要组成部分,但其本身并不构成人工智能系统,人工智能模型需要添加更多组件(如用户界面)才能成为人工智能系统。通用模型带来了真正的变革,过去每一次关键技术(如蒸汽机、电力、互联网等)的通用性得到解决后,生产方式都有巨大改变,生产力水平也发生质的飞跃,人工智能是第四次科技革命的重要驱动力,通用模型则真正赋予其通用技术的关键特征,人工智能由此成为重要的元技术,催生出一系列二次创新和变革,全方位赋能和改变人类的生产生活。
通用模型的法律治理仍处于早期探索阶段,绝大多数国家尚未明确将其纳入规制体系,现有研究文献亦多着眼于系统层,鲜少关注模型层。本文将聚焦通用模型的法律规制,从医疗领域切入,深入探讨模型规制的关键议题。之所以选择从医疗领域切入,既非心血来潮,亦非故弄玄虚,而是具有充分的理由。一则言之有物。医疗是人工智能落地最早、应用最广泛的两大领域之一,医疗AI属于医疗器械范畴,包括中国、美国等在内的各国监管机构已经批准了数量众多的医疗AI。根据国家卫生健康委员会披露的资料,我国已有不少医疗AI临床部署的案例,散布于东中西部地区,遍及医学影像、呼吸、消化、心血管等常见科室。更重要的是,通用模型已开始广泛赋能医疗健康产业,在辅助诊断、辅助治疗、医药研发等领域均有深度探索和应用。因此,从医疗领域切入将使我们的讨论更加具象和生动。二则典型示范。医疗AI关乎患者生命健康,属于典型的强监管领域,我国已构筑起全流程的医疗AI管理制度,包括前端的准入审核(如《人工智能医疗器械注册审查指导原则》等)、中端的临床使用(如《人工智能辅助诊断技术管理规范》等)和后端的不良事件监测及产品召回(《医疗器械监督管理条例》)等。其他应用领域则往往有所缺失,例如,汽车自动驾驶算法通常只需备案,仅L3及以上自动化分级须经审批,目前国内外自动驾驶的主流水平为L2级及以下。此外,医疗AI注册审评已开始关注上游模型评价问题,国家药品监督管理局发布的《人工智能医疗器械 质量要求和评价 第5部分:预训练模型》(YY/T 1833.5-2024,2024年9月颁布、2025年10月实施)即将审评范围延展至“预训练模型”,提出了模型评价的主要维度,包括可迁移性、一致性、健壮性和泛化性等。医疗领域处于人工智能系统和模型规制的最前沿,从医疗领域切入有助于我们展开深入的制度研讨,形成缜密的应对方案。三则因势利导。通用模型的发展应用具有鲜明的层级结构和体系特征,并最终落脚于具体的行业,具有强烈的行业导向属性。国内主要通用模型厂商(如百度、华为、阿里巴巴等)的开发体系对此有生动注解(见图1)。这种层级结构顺应了通用模型的训练规律,即在“基础层”和“任务层”完成“通识教育”获取基础能力,在“行业层”完成“专业教育”获取专业能力,这与人类接受教育的历程相似。从医疗行业切入,更加契合通用模型的开发和应用规律,亦将使我们的讨论更加务实和聚焦。由此,笔者将以医疗领域为例,首先阐释通用模型的技术演进和范式变革,进而探讨通用模型的规制现状及治理挑战,最后提出针对性的规制策略和方案。
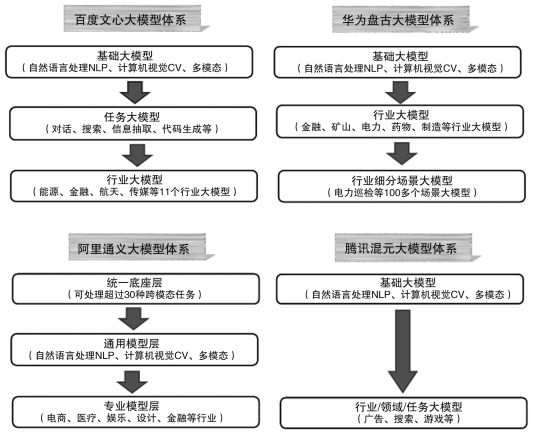
图1 百度、华为、腾讯、阿里巴巴的大模型开发体系
一、通用模型的技术演进及范式变革
“法之理在法外”。作为一种新型人工智能,深刻洞察通用模型的技术演进和运行逻辑是我们展开理性法学研讨的前提。国内法学文献普遍缺乏对通用模型技术逻辑的精准阐释,这在一定程度上造成了概念偏倚和自说自话。本文希望结合国内外权威科学文献,系统阐释通用模型的演进路径。
(一)传统模型的技术流变和应用局限
通用模型的诞生是自然而然的历史过程,通往通用模型的桥梁来自于传统模型的应用局限。人工智能整体经历了从基于规则(rulebased)的系统转向基于数据(databased)的系统的演进脉络,目前运用的主流技术是机器学习(Machine Learning,ML)。机器学习依据统计学方法对大量历史数据进行学习以总结和提炼规则,相较于传统算法,机器学习基于数据而非规则,它并非按照预先设定的规则重复演算,而是从数据中学习和提炼规则,这便将人类从复杂的算法抽象中解放出来。2006年,机器学习的最新子集深度学习(Deep Learning,DL)被提出,它模拟人脑神经网络的多层计算结构,在编程中引入多个隐藏层(layer),以多层自编码的形式进行演算,打破了人工智能的发展瓶颈,例如,在深度学习算法引入前,语音识别的准确率连续三年稳定在76.4%,新算法引入后,准确率逐年递升至94.5%(2017年)。
根据笔者的检索,医疗领域目前应用的AI算法主要为深度学习。深度学习包含了多种算法架构,常见如卷积神经网络(Convolutional Neural Networks, CNN)和递归神经网络(Recursive Neural Network,RNN),它们都是先进的算法架构,已经在很多任务领域达到甚至超过人类水平。但是,传统深度学习针对特定任务而设计,应用范围较为狭窄,不具有通用性,属于特定任务模型范畴。这在已获批的医疗AI上体现的尤为明显。美国食品药品监督管理局(Food and Drug Administration,FDA)核准注册的500多个医疗AI中,绝大多数只被批准用于一至两项狭窄的任务,例如,胸部X射线肺炎检测系统,只能用于肺炎检测,无法撰写全面的放射学报告。截至2024年12月,我国已批准百余款作为第三类医疗器械管理的医疗AI(仅统计独立软件,不包含软件组件),覆盖心血管、脑部、眼部、肺部、骨科、肿瘤等多个诊疗领域,预期用途包括分诊评估、定量计算、病灶检测、靶区勾画等。但正如表1所示,我国注册的医疗AI绝大多数仅可胜任一项特定的诊疗任务,如计算深脉血流储备分数、肺结节检测、肺炎检测、糖尿病视网膜病变检测等,仅个别可胜任两项及以上任务,如眼底病变眼底图像辅助诊断软件(序号23)可同时检测糖尿病视网膜病变和可疑慢性青光眼样视神经病变,但也基本属于同一诊疗领域的相近任务。


特定任务模型或系统具有明显的局限性。以卷积神经网络(CNN,模仿人类视知觉的深度学习模型)为例,它仅能胜任特定的诊疗任务,通用性差,如果切换到其他任务类别,便需要重新设计和训练,效率低下,成本高昂。而且,训练CNN需要高质量的标注数据,通常由医疗专家标注,这导致人力成本的膨胀。更重要的是,CNN已被反复确证在场景迁移和算法泛化中存在先天的局限,这导致其在从高资源环境(如区域中心医院)转向低资源环境(如社区医院)、从白色人种转向有色人种、从高收入人群转向低收入人群、从发达地区转向欠发达地区时存在原生障碍,容易诱发诊疗偏差。此外,特定任务模型时常会犯人类可轻易避免的错误。例如,将身体上的刺青诊断为皮肤癌,原因在于,它缺乏必要的背景知识和上下文理解能力,仅通过统计学分析输出诊疗决策。特定任务模型尽管仍在取得创新,但与人类期待相去甚远,新型人工智能呼之欲出。
(二)通用模型的技术演进和范式变革
谷歌(Google)团队于2017年提出了著名的Transformer架构,正式拉开了通用模型的发展序幕。Transformer架构完全基于注意力(attention)机制而设计,彻底省去了递归神经网络(RNN)和卷积神经网络(CNN)。注意力机制是Transformer架构的关键组件,它的最初灵感来自于人类的视觉习惯,当人用眼睛进行观察时,会首先快速扫描全局图像,然后再捕捉需要重点关注的目标区域,并对目标区域投入更多的注意力资源,忽略其他区域。相较于RNN、CNN等传统架构,Transformer架构具有三大显著优势:第一,它可以有效获取长距离信息,从而实现全域的上下文理解,CNN、RNN等普遍存在长距离信息丢失的问题;第二,它可以实现并行计算,从而大幅提升计算效率,CNN、RNN等只能进行串行计算;第三,它具有更强的通用性,与特定任务或领域没有强烈的关联,这有助于增强下游适应性,RNN和CNN则先天受限于语言和视觉模态的固有属性。由此,以Transformer架构为基础、以预训练和无监督学习为支撑、可广泛适应下游任务的通用模型应运而生。
技术架构的创新是通用模型诞生的重要基础,但学界更倾向于将其界定为一场深刻的“范式变革”,而非“技术变革”。原因在于,Transformer架构仍属于深度学习范畴,是在深度学习框架内的技术演进,深度学习的一个重要特征就是可以在代理任务上进行训练,而后根据具体应用场景进行微调,此即所谓的“迁移学习”,它已经存在了几十年,我国药品监督管理局发布的《人工智能医疗器械注册审查指导原则》(以下简称《指导原则》)就明确界定了“迁移学习”,即“将在某领域或任务学习到的模型应用于不同但相关的领域或任务的人工智能算法,如将在自然图像领域学习形成的模型应用于医学图像领域”。无监督学习亦属于机器学习的传统分支,划分依据在于学习策略要素,是一种“无需对训练数据进行标注”的学习技术,并非全新技术。可见,通用模型之要义不在于技术的单点突破,而在于要素组合和发展范式的变革。“预训练+微调”的新型范式将迁移学习与无监督学习在Transformer架构下有机整合,促使训练数据几何量级增加,最终推动量变向质变的飞跃。科学界之共识在于,数据和参数的巨大规模是模型能力跃升的直接诱因,GPT模型便是“暴力计算”和“大力出奇迹”的典范,通用模型亦常被称为“大模型”。因此,通用模型的横空出世本质上是一场“范式变革”,而非“技术变革”。
这并无任何贬低之意味,通用模型的“范式变革”带来了极其深远的影响。通用模型向我们指明了通往通用人工智能(Artificial General Intelligence,AGI)的可行路径,将带来真正的通用性革命。以医疗领域为例,通用模型有效化解了传统医疗AI临床应用的痛点难点,开辟了人工智能与医疗场景深度融合的新范式。第一,由于风险收益的错配、医疗机构的数据竞争以及单独同意的法律构造,社会面可公开获取和共享的医疗数据十分有限,加之高昂的标注成本,医疗AI的开发和应用受到严重抑制,通用模型则可在很大程度上化解该问题,预训练阶段可以非医疗数据(如自然图像)替代医疗数据(如医学影像),微调(或后向开发)阶段亦仅需少量的专家标注数据即可胜任特定场景任务。科研院所目前发布的医疗大模型多源自Meta公司的开源模型LLaMA,LLaMA模型依托广泛数据训练而来;医疗大模型(如MedAlpaca、NHSLLM、ChatDoctor、DoctorGPT)则依托开源模型并利用医疗数据集后向开发而来;大型科技公司研发的医疗大模型也多源自其基础大模型,例如,百度公司依托“文心大模型”开发出“灵医大模型”,腾讯公司依托“混元大模型”开发出“腾讯医疗大模型”,后段开发所需的医疗数据体量显著减少。第二,传统模型在泛化和适应能力上存在先天缺陷,难以应对分布的变化(即因环境或人群等变化而引起的数据分布变化),通用模型则可通过对下游情境的持续学习(即微调)有效适应分布的变化。例如,医院通过提供少量的实例提示,即可引导通用模型成功解读全新X射线仪扫描的医学影像素材,无需在全新数据集上重头训练。斯坦福大学等的研究表明,以电子健康记录(EHR)为预训练样本的通用模型在临床结果(包括住院死亡率、30天再次入院概率和ICU入院概率等)预测上具有明显的分布外(outofdistribution,OOD)优势。第三,传统模型仅能胜任狭窄的任务领域,临床获益严重受限,通用模型则可适应广泛的下游任务,临床获益显著提升。在国外,哈佛大学医学院研发的医疗大模型CheXzero单次扫描胸部X射线影像后即可检测数十种疾病,显著提升了医疗AI的使用效率和临床获益。在国内,温州眼视光国际创新中心(中国眼谷)研发的眼科专用大模型EyeGPT可以同时胜任多种眼科疾病的辅助诊疗,包括视网膜病变、青光眼、眼癌、近视等,北京邮电大学研发的医疗大模型ClinicalGPT的辅助诊疗范围覆盖呼吸、消化、泌尿、精神病学、神经病学、妇科和血液学等诸多科室。第四,传统模型通常缺乏医学领域知识,仅依赖输入数据与预测目标之间的统计学分析推导数据关联,缺少病理和生理过程梳理,这可能导致医疗AI陷入常识性错误,通用模型则具有更复杂的网络结构和更多参数,结合知识图谱等技术,可以预先学习大量医学和非医学知识,深入理解医学概念及其相互关系,具备强大的背景梳理和逻辑推理能力(DeepSeekR1模型即以强大的推理能力而著称),可以有效避免常识性错误。
二、通用模型的规制现状及治理挑战
通用模型的出现掀起了AI发展的新浪潮,推动人类社会全面、快速步入智能化时代。同时,通用模型的实践应用也带来了各种新风险,如缺陷传导风险、智能涌现风险等,并可能经由模型和数据的转介放大既有风险,如歧视偏见风险、隐私泄露风险等,这需要引起充分重视并积极应对。作为新兴事物,通用模型的法律治理仍处于早期探索阶段,目前来看,绝大多数国家或地区尚未将通用模型纳入规制体系,根本原因在于通用模型的特殊性,正如HAI报告所言,通用模型本质上是一项中介资产(intermediary asset),它没有明确的目的和任务,属于中间形态和未完成形态,虽然构筑了处理广泛下游任务的共同基础,却并未直接参与和执行任务。形象而言,通用模型犹如蚁群中的蚁后,体型庞大,深居蚁穴,专司繁育,具体事务则交由工蚁兵蚁(由蚁后繁育,恰如由通用模型繁育而来的应用系统)外出执行,这与以特定目的为导向的传统规制体系存在天然冲突,此为当下面临的最大现状及挑战。
(一)我国的规制现状及治理挑战
仔细梳理现行AI相关立法,我国并未对通用模型提出明确的规制要求,这在医疗领域体现得尤为明显。医疗AI属于医疗器械范畴,我国现行医疗器械立法围绕诊疗应用系统而构建,并未延伸至上游的模型领域。例如,《医疗器械监督管理条例》的规制对象是医疗器械,“医疗器械是指直接或者间接用于人体的仪器、设备、器具、体外诊断试剂及校准物、材料以及其他类似或者相关的物品,包括所需要的计算机软件”,诊疗软件亦可构成医疗器械,但其明确指向终端应用软件,而不包括中间形态的通用模型。《指导原则》进一步规定,“人工智能医疗器械是指基于‘医疗器械数据’,采用人工智能技术实现其预期用途(即医疗用途)的医疗器械”,明确以“预期用途”限定注册审查范围。应当指出,在医疗AI场域,审查机关已经意识到系统与模型之间的紧密关联,并尝试进行必要的延展审查,例如,针对迁移学习技术的运用,《指导原则》规定,“人工智能医疗器械若使用迁移学习算法,注册申报资料需明确算法的名称、类型、输入输出、流程图、运行环境等基本信息以及算法选用依据,并根据迁移学习的类型及其算法特性提供预训练模型的数据集构建、算法测试等资料”,但囿于医疗器械监管的固有逻辑和底层架构,文件仅要求医疗AI申报人提供预训练模型的相关资料,而未提出明确的规制要求,属于形式化附带审查范畴,缺乏明确的实质性标准。此外,《人工智能医疗器械 质量要求和评价第5部分:预训练模型》是目前极少数涉及预训练模型的治理文件,要求医疗AI申报人对预训练模型进行“说明和描述”,但仅提供了评价方向和框架,而未设定具体标准。例如,文件提出了预训练模型质量评价的主要维度,包括可训练性、架构可扩展性、可迁移性、模型效率、输出一致性、健壮性、泛化性等,但仅有概览性描述,并无具象性标准。更重要的是,该文件属于推荐性行业标准,不具有法律强制力,并于开篇明示其“不对预训练模型的研发过程进行约束”,也就是说,预训练模型的“说明描述”仅为医疗AI质量验证的必要延展,而不构成独立治理对象。
我国AI一般性立法亦未将通用模型纳入规制体系。例如,《生成式人工智能服务管理暂行办法》(以下简称《暂行办法》)的规制对象是生成式人工智能服务,即“利用生成式人工智能技术向中华人民共和国境内公众提供生成文本、图片、音频、视频等内容的服务”,直接面向下游用户,属于应用系统范畴。《暂行办法》第7条虽提及“基础模型”,要求生成式人工智能服务的提供者“使用具有合法来源的数据和基础模型”,但是,监管对象是应用系统提供者,基础模型提供者应当承担何种义务,未有明确规定。正如学者所言,我国AI监管领域基本呈现“技术支持者—服务提供者—内容生产者”的框架体系,其中,服务提供者是重点监管对象,内容生产者是一般监管对象,技术支持者则很少受到硬性监管约束,主要适用AI伦理等软性要求。《暂行办法》基本沿袭此一框架和路径,附则部分对“生成式人工智能服务提供者”(服务提供者)和“生成式人工智能服务使用者”(内容生产者)的概念进行了明确界定,正文部分亦围绕此二者建构规制体系,惟独缺少对“生成式人工智能模型提供者”(技术支持者)的界定和规制。
通用模型的规制缺位带来了巨大的风险和挑战。通用模型赋予AI以通用技术的关键特征,可广泛适应下游任务,这一方面意味着能力和效率的显著提升;另一方面也意味着模型缺陷的普遍传导和继承。研究显示,通用模型愈发具有同质化(homogenization)趋势,几乎所有最先进的自然语言处理模型都改编自少数几个经典模型,如BERT、RoBERTa、BART和T5。计算机视觉、语音识别等其他领域亦是如此。同质化现象进一步加剧了模型缺陷的下游传导。通用模型的涌现特性也是风险和挑战的重要来源。所谓智能涌现(intelligent emergence),意指产生未曾设想之新能力,此种特性赋予通用模型以惊人能力和无限潜力,但同时也意味着模型行为是隐式诱导而非显性构建,它既是科学兴奋的来源,也蕴藏着意外后果的焦虑。同质化和智能涌现正以一种潜在的令人不安的方式相互作用:同质化将模型自身缺陷向下游应用广泛传导,而智能涌现既是模型力量的源泉,也具有意外的故障模式,对现有非经明确构造且难以理解的模型进行激进的同质化暗藏着巨大风险。此外,优质的开源模型如DeepSeekR1以公开和免费的方式对外发布,允许任何人根据许可条款下载、修改和分发,天然具有更强的传播力和扩散性,已在极短的时间内被整合进各类下游应用系统,多家医疗机构(如浙大邵逸夫医院等)已宣布本地部署DeepSeek模型,将模型能力整合进医院的管理系统,这进一步加剧了模型缺陷的快速传导风险。更重要的是,现行体系缺乏上游回溯和纠偏机制,即便下游应用环节发现“遗传性”缺陷,亦将无法及时识别、分析和化解,这在医疗领域尤为突出。医疗AI属于强监管领域,强调风险的集中、全程和源流管控,根据《医疗器械监督管理条例》之规定,医疗器械注册人在其中扮演着关键角色,对医疗器械质量在其全生命周期和应用环节(包括但不限于研发、生产、销售、上市后管理等)承担质量管控责任,成为风险管理的中心,负有全面及全流程之义务,包括建立并运行质量管理体系、监督生产和流通、制定并实施上市后研究计划、开展不良事件监测和再评价、建立和执行追溯和召回机制等。然而,医疗AI属于应用系统范畴,医疗AI注册人属于应用系统提供者,这便意味着,现行监管框架仅能溯及医疗AI注册人,而无法继续向上追溯至通用模型提供者,鉴于通用模型与应用系统之技术连结、数据贯通及风险传递,追溯链条的中断必然引发体系性风险。
(二)域外的规制现状及治理挑战
放眼寰球,绝大多数国家或地区尚未将通用模型纳入规制体系。例如,作为AI技术开发的领先区域,美国联邦基本秉持“创新驱动、监管辅助”的政策导向,很少对AI技术开发设定硬性约束,而主要通过软法及市场化手段开展治理。美国联邦已发布不少框架性和指导性文件,如《人工智能风险管理框架(Artificial Intelligence Risk Management Framework,AIRMF)》《人工智能权利法案蓝图(Blueprint for an AI Bill of Rights)》等,此类文件主要是引导属性,依赖于企业自治和行业自律。2023年7月,美国白宫与七家领先的AI公司(Amazon、Anthropic、Google、Inflection、Meta、Microsoft、OpenAI)举行闭门会谈,获后者自愿承诺推进AI技术的安全、可靠和透明发展。2024年2月,200多家美国AI实体加入美国商务部国家标准与技术研究所(NIST)设立的人工智能安全联盟(AI Safety Institute Consortium,AISIC),自愿承诺在产品发布前进行内部和外部的安全测试,并与政府、民间社会和学术界分享管理 AI 风险的信息。可见,美国联邦对AI的直接规制很少,即便AI系统的开发亦很少受到硬性约束,遑论通用模型。应当指出,根据美国的宪法设计,药品和医疗器械的监管权限属于联邦政府,美国医疗器械监管制度主要依据《联邦食品、药品和化妆品法案(Federal Food, Drug, and Cosmetic Act,FDCA)》构建,监管机关为食品药品监督管理局(Food and Drug Administration,FDA),监管对象为直接面向诊疗实践的产品,即“用于诊断、治疗、缓解、处理或预防人类或其他动物的疾病的植入或非植入的器具、仪器、工具、机器、机械装置、试剂或者其他类似或相关物品”,就医用软件而言,主要指各类面向终端实践的辅助诊疗系统,不包括上游的诊疗模型。2016年发布的《21世纪治愈法案》(the 21st Century Cures Act)专门针对医疗AI的监管权限进行了厘清,明确将提供诊断或治疗服务的AI系统纳入FDA监管权限,而将仅提供健康监测、咨询服务的AI系统排除在外。但是,FDA监管体系的落脚点始终在于AI系统的安全有效性,并未将监管触角延展至AI模型。
美国各州针对通用模型的立法动向值得关注,代表性案例为加利福尼亚州《前沿人工智能模型安全可靠创新法案(the Safe and Secure Innovation for Frontier Artificial Intelligence Models Act,简称SB1047法案)》。SB1047法案所界定的“前沿模型”是最先进的通用模型,即在训练过程中达到最低财务或计算资源投入标准的通用模型,目前仅极少数模型可被涵盖。SB1047法案对通用模型的开发者(developer)进行了明确而直接的规制,设定了广泛而严苛的义务,这是显著的立法突破。根据法案规定,在首次训练模型前,开发者应当:(1)实施特定的技术和组织措施以减缓模型相关风险;(2)具备迅速、全面关停模型(“一键关停”)的能力;(3)制定和实施符合要求的安全保障协议等等。在将模型投入商业、公共或其他用途前,开发者应当:(1)进行模型安全评估,评定造成或促成严重损害的可能性;(2)采取适当措施,防止模型造成或促成重大损害;(3)通过合理谨慎的安排,保证模型行为及其引发的关键危害能被准确归因等等。此外,模型开发者还应持续承担下列义务:(1)每年重新评估法案遵守情况,包括聘请独立的第三方机构进行合规审计;(2)当获悉发生基于模型的安全事故时,于72小时内向司法部长报告等等。可见,SB1047法案不但将通用模型明确纳入规制体系,而且设定了全面严苛的义务,建构起通用模型法律规制的完整框架,但这种强硬的规制立场引起了广泛的反对,在SB1047法案分析文件的官方附录中,明确支持该法案的机构有43家,反对者则多达159家。鉴于美国加州拥有《福布斯(Forbes)》全球50强人工智能公司中的32家,是全球AI创新和发展的中心,如若SB1047法案顺利通过,将对美国乃至全球AI监管政策产生重大影响。遗憾的是,SB1047法案最终因加州州长的反对而未能生效。
目前极少数直接规制通用模型的代表性区域是欧盟,已生效的欧盟《AI法案》明确将通用模型视作重要的风险点,并为其设定了针对性规则。纵观立法进程,欧盟《AI法案》对待通用模型的态度可谓“反复犹疑”。最初版本(2021年)的《AI法案》并未料及通用模型的迅猛发展,未将其纳入规制体系,仅为AI应用系统构建了基于风险(riskbased)的规制架构,区分应用系统的不同风险程度(不可接受风险unacceptable risk、高风险high risk、有限风险general risk和风险最小minimal risk)配置不同的规制措施。2022年底,ChatGPT风暴席卷全球,《AI法案》应激性的将通用模型直接归入高风险AI系统,进行全面和严格的管理,这招致了广泛的批评。而后,《AI法案》又走向另一极端,将通用模型完全排除于规制范围,仅使下游应用系统的提供者(provider)和部署者(deployer)承担风险管理义务,通用模型的开发者仅需协助提供“必要、相关和合理预期的信息”。这种做法明显脱离实际,不利于AI价值链的安全、稳定和可信。经过反复和激烈的讨论,最终通过的《AI法案》采取了折中方案,一方面仍将高风险应用系统的提供者作为最重要的义务和责任主体;另一方面则将通用模型提供者纳入规制体系,赋予其多项义务。欧盟《AI法案》将通用模型区分为普通通用模型和具有系统性风险(systemic risk)的通用模型,后者为规制重点。普通通用模型的提供者仅需承担少量的透明度义务,而具有系统性风险的通用模型提供者还应承担下列义务:(1)首次投放市场前,对模型进行必要评估,包括对模型进行对抗测试并记录在案;(2)持续评估模型运行的系统性风险,并在模型全生命周期内采取适当措施降低风险;(3)当发生严重事件时,及时跟踪、记录和向欧盟AI办公室报告,并采取可能的纠正措施;(4)确保向模型及其物理设施提供充分的网络安全防护等。
就欧盟法而言,医疗AI是一个相当特殊的领域,除《AI法案》外,医疗AI还应适用欧盟有关医疗器械的统一条例和指令,包括2017/745号条例、2017/746号条例、93/42/EEC指令(《医疗器械指令(Medical Devices Directive,MDD)》)等,但二者在不少方面存在差异甚至冲突。例如,《AI法案》第8条为高风险人工智能系统设定了“合格性评估制度”,这本质上是一项认证机制,而非行政许可,包括自我认证和第三方认证,而医疗AI(医疗器械)的注册审查属于典型的行政许可,须经严格的安全有效性测试和审查;再如,MDD的规制对象是医疗器械,包括人工智能医疗器械,属于应用系统范畴,并未延展至上游模型,《AI法案》则明确将通用模型列为规制对象,赋予其实质性义务,更重要的是,《AI法案》重点规制对象(即具有系统性风险的通用模型)之界定依据在于“系统性风险”,“系统性风险”之界定要素在于“高影响能力”,即“与先进水平的通用模型中记录的能力相匹配或超过这些能力的能力”,而MDD强化规制的主要理由则在于诊疗领域的高风险性,落脚点在于应用领域而非固有能力。因此,二者在规制理念和方式上存在明显分歧,医疗领域模型可能因未及“高影响能力”标准而被划归普通模型范畴,这无疑潜藏着巨大风险,欧盟目前尚未就此构建有效的协调机制。
三、通用模型的立法涵摄及规制策略
通用模型的规制缺位潜藏着巨大风险,立法者应当敦本务实,明确将通用模型提供者纳入规制体系,消弭法律制度与技术现实之鸿沟。同时,立足通用模型的技术特性和体系定位,合理选定规制策略,精准适度赋予法律义务,实现制度安全与技术创新之平衡。
(一)通用模型的立法涵摄:明确纳入规制体系
在“预训练+微调”的新型范式下,通用模型提供者居于人工智能价值链(AI value chain)的关键位置,对价值链之安全、稳定和可信影响重大,理应纳入规制体系。AI价值链是对AI组织过程(organizational process)的科学描述,是AI立法的重要线索。“人工智能价值链”一词于欧盟《AI法案》(含序言)前后出现十余次,横贯始终,AI的法律治理本质上就是围绕AI组织运行中的不同实体分配法律义务、构建法律制度的过程。欧盟《AI法案》所建构之价值链条和法律身份具有较高的合理性和代表性,鉴于此,下文将以之为参照展开论述。欧盟《AI法案》主要提炼了九种法律身份,即通用模型提供者(provider of GPAI model)、应用系统提供者(provider of AI system)、应用系统部署者(deployer of AI system)、受影响者(affected person)、授权代表(authorized representative)、进口者(importer)、分销者(distributor)、经营者(operator)、下游提供者(downstream provider)等,其中,前四种法律身份属于全场景法律身份,而“授权代表”“进口者”和“分销者”属于特定场景的特殊法律身份,“经营者”则是“提供者、产品制造者、部署者、授权代表、进口者或分销者”的统称,属于集合型概念,“下游提供者”则是为彰显模型与系统的上下游关系而创设的特殊概念,属于“应用系统提供者”的子概念,由此,人工智能价值链的组织骨架主要由四种全场景法律身份所搭建,如图2所示。
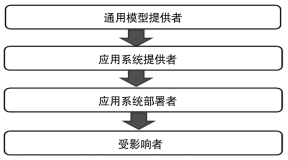
图 2欧盟《AI法案》人工智能价值链的组织骨架
通用模型提供者位于AI价值链顶端,构成一系列下游应用的基础,属于智能生态的关键节点。较之传统软件,现代AI之重要特性在于算法和数据的双轮驱动,数据要素愈发重要,机器学习意味着数字系统不再需要完全编程,而可通过后续的数据投喂不断学习和成长,编程人员不再需要预先知晓系统运行的所有可能状态,系统行为也不再完全由编程人员预先设定。OpenAI的著名论文《Scaling Laws for Neural Language Models》表明,训练数据量和参数量成为影响通用模型性能的关键要素,模型性能表现与规模强相关。与算法弱相关。简言之,模型越大,性能越好,单纯增加训练数据量和参数量即可提升模型性能,且暂未见其瓶颈。通用模型提供者是数据和代码的最重要贡献者,它设计了模型的算法架构,并以大量数据开展预训练,由此塑造了模型的基本形态和性能边界。通用模型愈发具有基础设施属性,成为支撑社会数字化转型的智能底座。在很短的时间内,DeepSeek模型已被我国政务机构(如广东、江苏)、企业巨头(如中国移动、腾讯)和科研机构(如浙江大学、武汉大学)等各种类型的下游用户整合进其管理和服务系统,提升运营效能,实现智能升级。这也意味着,通用模型提供者是生态风险的重要制造者,数据及代码瑕疵将广泛、直接和快速地传导至下游系统,可能引发“遗传性”和“系统性”风险。通用模型上游风险的一个极端例子是利用其设计化学武器。一家制药公司研究发现,借助通用模型可在6小时内生成40 000个剧毒分子结构,允许对这些分子的杀伤力进行任何进一步的分析是不道德且危险的。此外,通用模型提供者也是利益分配的主导者,它不但攫取了利益的最大份额,而且具备强大的生态控制能力,逐步走向自然垄断,基于算力、数据和算法的独占优势,通用模型市场最终将演化为类似传统互联网领域(如搜索、社交、电子商务等)的寡头垄断格局,具有系统重要性的实体(如微软、谷歌、OpenAI)正利用定制的高级计算资源和专业知识、代表真实世界部署和用例的大量数据,以及跨人工智能和非人工智能客户群的规模经济,塑造智能生态,控制下游行动。因此,将通用模型提供者纳入规制体系,具备充分的正当性。
在医疗领域,通用模型的立法涵摄更具紧迫性。通用模型范式变革前,医疗AI价值链的主要参与者包括医疗AI提供者(医疗器械开发者)、医疗AI部署者(医疗机构)和受影响者(患者),而当“预训练+微调”成为辅助诊疗系统的新开发范式,通用模型之立法涵摄尤显刻不容缓。分三点述之。其一,医疗AI关乎患者生命健康,尤为注重事前准入,需开展充分的安全有效性验证,通用模型的规制缺位将导致医疗AI事前准入体系的重大漏洞和隐患。医疗AI是典型的强监管领域,风险管理的重心在于事前审查,注册审批是临床应用之前提,而事后弥补则具有德性瑕疵及有限性,与娱乐、购物、社交等泛生活化场景的AI系统的事后规制或事前备案治理方式相比,专业化场景的医疗AI需经严格的准入审批。鉴于医疗AI与通用模型之算法同根、数据同脉及风险同源,通用模型之立法涵摄为构建完整可靠的事前准入体系所必需。此外,医疗通用模型将显著扩展医疗AI的影响范围和强度。一方面,医疗通用模型可快速、大量孕育不同类型的医疗AI,开启医疗AI的工业化生产时代;另一方面,医疗通用模型也可提升同类型医疗AI的诊疗能力,拓展任务边界,医疗通用模型甚至被赋予孕育万能医生(Generalist Medical Artificial Intelligence)的宏大使命,接收多模态数据,开展高维推理,适应未知任务,超越人类智识边界,这已超出个人安全范畴,关乎人类族群命运。可见,医疗通用模型之立法涵摄事关重大。其二,医疗AI的现行验证体系依托于医疗器械监管框架,验证范围和能力都有明显的局限性,这与医疗通用模型的广阔能力和涌现特质存在天然冲突。医疗AI的技术验证有赖于临床评价,主要通过临床试验等方式展开。临床试验围绕安全有效性的验证目标而设计,各国一般将药品和医疗器械的临床试验划分为三个阶段:第一阶段为药械安全性的基本试验(Ⅰ期);第二阶段为药械有效性的有限试验(Ⅱ期);第三阶段是扩大受试人群后的安全有效性延展试验(Ⅲ期)。药械临床试验的范围是极其有限的,即便到达Ⅲ期试验,法定最低病例数(试验组)要求仅为300例,开发实践中的病例样本多处于百千量级。这在传统AI时代或许可以接受,但在大模型时代,训练数据由GB量级跃升至TB量级,模型参数动辄百亿千亿计,加之讳莫如深的智能涌现,仅仅依赖应用层级的有限验证,而不对通用模型进行直接规制,根本无法达到合理的验证标准。人类对生命和疾病的认知有限性与通用模型的能力无限性(未知性)要求我们必须突破应用层级的法律规管,对通用模型采取直接而精准的规制措施,不拘泥于形式化的附带或延展审查,尽量防范所有已知或未知的风险。其三,在“预训练+微调”开发范式下,医疗AI的风险形态由分散走向集中,这客观上要求规制体系上移,明确涵摄通用模型,从而实现风险的源流管控。医疗通用模型是面向复杂、开放诊疗场景的基础模型,具有大数据、大算力、大参数等关键要素,呈现涌现能力和良好的泛化性、通用性,可以根据不同的诊疗任务,利用语言、视觉、语音乃至多模态融合的生物医学数据调适特定场景的辅助诊疗系统,这在客观上导致了诊疗风险的集聚和同质。医疗通用模型呈现出鲜明的家族化特色,已发布的医疗健康大模型多以GPT、BERT等为后缀,形成家族化谱系,例如scGPT、MolReGPT、CancerGPT、MedGPT、MedBERT等,这进一步加剧了诊疗风险的汇流和集中。医疗通用模型逐步成为医疗AI孕育的母体,模型瑕疵和缺陷随之向下游应用系统普遍传导和扩散,医疗AI的风险形态逐步由分散走向集中,共性风险不断增加,通用模型被赋予智能诊疗底座的角色,成为数字诊疗市场的“守门人”。就此而言,监管机关理应将通用模型提供者纳入规制体系。
(二)通用模型的规制策略:精准适度分配法律义务
立法涵摄之下,我们应当基于通用模型的体系定位和技术特性精准适度分配法律义务,防止责权错配抑制创新。笔者认为,通用模型提供者的义务导向是智能生态的一般安全,没有特定的目的和场景,属于抽象性义务,通用模型提供者应当对模型品质承担一般保证义务,持续监测生态运转,修复模型缺陷,维护生态安全。通用模型提供者的义务重心在于内在评价(intrinsic evaluation),即专注评估通用模型的内在品质,不设想具体的下游任务,聚焦于模型架构的科学性、数据治理的有效性、训练方法的适当性、开发组织的合规性、开发人员的多样性和代表性以及开发流程的规范性等一般事项。这是科学合理的法律设定。作为一项没有明确用途的中介资产,构建基于通用模型的全面风险管理体系几乎不可能,它将迫使模型开发者识别和分析由其衍生的所有可能应用程式的风险,制定和实施所有风险的缓解策略,并开展所有预期场景的准确性、稳健性和网络安全性测试,整个分析必须基于抽象的假设性调查,并结合再次假设的风险缓解措施和性能测试,这不仅成本高昂,而且完全不可行。欧盟《AI法案》对通用模型提供者的义务定位具有类似取向,例如,通用模型提供者主要承担抽象性的风险管理义务,包括透明度义务(即编制和更新技术文件信息)、模型评估义务和软硬件安全防护义务等,不对特定场景的具体风险负责。相反,美国SB1047法案的失败在很大程度上可归因于对通用模型提供者的过度苛责,模型开发者不但被要求采取全面的风险减缓措施,而且需要对具体应用场景的系统损害承担繁重的民事责任,包括民事罚款、损害赔偿和惩罚性赔偿等,这遭致了激烈的反对。与之相对,应用系统提供者的义务导向是特定应用场景的具体安全,属于具象性义务,应用系统提供者应当对系统品质承担具体保证义务,持续监测系统运行,建立有效的风险管理体系,维护场景应用安全。应用系统提供者的义务重心在于外在评价(extrinsic evaluation),即专注于应用系统在特定场景中的性能表现,主要从预期用途、使用场景、核心功能等维度建构评价体系,重点规制措施为合格性评估(认证性)或注册审评(许可性)等。
在科学定位的基础上,我们应当区分通用模型和应用系统提供者的功能取向,精准、适度分配法律义务。同样以医疗领域为例,笔者建议构建两阶段的准入审核体系,分别设定审查标准。两阶段的准入审核体系在医疗领域并不鲜见,例如,医疗机构的设置应经双重许可,即设置许可和执业许可,前者聚焦于医疗资源的宏观配置(区域医疗资源发展规划),后者聚焦于申请者的自身禀赋(医疗机构的运营标准);再如,药品管理领域的上市许可持有人执照制度,要求申请者首先获得特定类别的准入执照,而后才能申请成为特定药品的上市许可持有人,执照准入有助于强化医药价值链的安全性和稳定性。医疗领域的两阶段准入审核体系有助于明确分工、提升韧性、强化全链条安全。据此,诊疗AI领域亦应构建两阶段的审核体系,各有侧重,各司其职(见图3)。第一阶段,医疗通用模型应当接受准入审查,确保AI价值链的源流安全,坚持内在评价,审查重点在于模型架构的科学性、数据治理的有效性、训练方法的适当性、开发组织的合规性等过程性事项,可借助标准化量表对模型品质进行测评考察。具体而言,通用模型参与者的主要义务包括:模型评估及品质保证义务,即采取必要措施,保证算法设计、数据集构建及模型训练的科学性和公平性,此一义务应定位为过程性义务,即采取符合要求的保障措施提升模型品质,并与现有技术发展水平相适应;网络安全防护义务,即在模型全生命周期内提供充分的网络安全保护,防范网络攻击,杜绝未经授权的访问等。第二阶段,医疗AI(由医疗通用模型孕育)应当按照医疗器械注册审评程序及标准接受二次审查,坚持外在评价,审查重点在于具体诊疗场景下预期用途和核心功能的达成性,审查方式为临床试验等结果性评价机制,“以算法特性为核心重点关注其泛化能力,以数据为基础重点关注其质控情况”。第二阶段审查目标聚焦于验证医疗AI处理特定诊疗任务的安全性和有效性,与之相应,医疗AI注册人担负的主要义务包括:应用评估和品质担保义务,即通过各种工具验证和保障辅助诊疗系统适应特定任务、达到特定品质,并履行具体的要素控制义务,包括数据治理、功能搭建、界面设计等,此一义务应定位为结果性义务,即通过各种方法和措施保证应用系统达到可合理预期的安全效用标准;风险监测和管理义务,即建立全面的风险监测系统,包括后市场监测及不良事件报告体系,实现风险监测和管理的闭环等。
在两阶段监管架构下,为进一步贯通及整合风险管理体系,笔者建议明确赋予医疗通用模型提供者以信息共享及行为协助义务,构建回流沟通机制。医疗通用模型提供者应当在尊重和保护知识产权的前提下,通过模型卡、数据表等方式共享模型信息,以使下游参与者清晰理解模型能力及局限,这是实现可信人工智能的制度保障。鉴于所处位置和技术资源,模型提供者应当成为协作规制的关键支点,就模型共性问题向下游参与者提供必要支持和协助。例如,当发生风险隐患或意外事件时,医疗AI注册人可先行分析原因、溯源风险和修复缺陷,若发现超出自身认知或能力,可继续向上游回溯、报告,医疗通用模型提供者应当及时响应请求,充分披露信息,积极开展缺陷定位及修复,并向下游其他支脉传递信息、警示风险,推动可信AI价值链的共享、共建和共治。
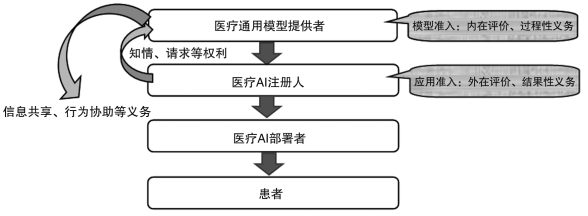
图3 医疗人工智能的价值链构造和准入体系
结语
我们正处于从网络时代迈向智能时代的关键转型期,以通用模型为代表的新一代人工智能正加速推动人类社会的智能化变革。通用模型真正赋予人工智能以通用技术的关键特征,使其成为如同电力、蒸汽机一样的元技术,全方位赋能和改变人类社会。同时,通用模型也会带来各种新风险,并可能经由模型和数据转介放大既有风险,这需要引起充分重视并积极应对。作为新兴事物,通用模型的法律治理仍处于早期探索阶段,包括我国在内的绝大多数国家或地区尚未将通用模型纳入规制体系,这是当下面临的最大现状和挑战。我国立法者应当明确将通用模型提供者纳入规制体系,消弭法律制度与技术现实之鸿沟,并立足于通用模型之技术特性及体系定位,精准、适度赋予法律义务,实现制度安全与技术创新之平衡。本文虽从医疗领域切入阐释通用模型的规制问题,但正如开篇所示,医疗领域之论证逻辑和制度方案具有强烈的示范效应,可有效迁移至其他领域。例如,同样关涉重要人身权益的强监管领域,如自动驾驶、刑事司法和行政执法等,亦可构建两阶段的准入审核体系;主要关涉财产权益的中度监管领域,如个人征信评估、保险理赔评估和劳动就业评估等,可适度放松管制,仅要求对通用模型进行登记备案;其他领域,如游戏娱乐、体育文化等,可进一步省略登记备案程序,仅要求承担必要的透明度和数据治理义务。通用模型的法律规制始终应当秉持场景化、行业化策略,将通用模型的开发和应用风险还原到具体行业和场景中,结合行业知识展开深入研究。
因篇幅限制,已省略注释及参考文献。原文详见《河北法学》2025年第5期。


